CNN 的前行計算之路即將來到終點,即將完成整個前行計算(Forward),有了 Convolution 計算、Pooling 以及 Activation 計算之後,我們只要在補完 Fully Connected Layer 以及 Loss Function就可以完成基礎的 CNN classification 應用了~~~
考完試還是要記得對答案呀!雖然你考30分你隔壁那個說沒看的98==
----阿峻20190925
我們再次參考上一章的圖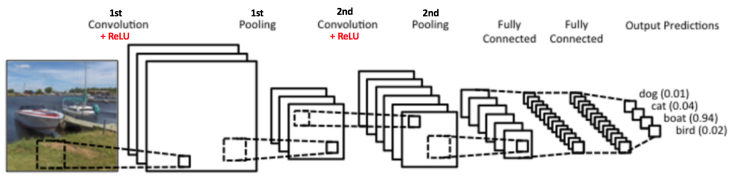
從這張圖我們可以看到在做完 Convolution layer,並用 Activation 以及 Pooling Function對結果的 Feature 進行運算後,最後我們需要把 Feature map (Feature vector) 餵進 Fully Connected Layer 做 Classification 以及計算 Loss,那麼這兩個要怎麼計算呢?就讓我們來看看吧~
在整個 CNN model 中,如果說前面的 Convolution layer 是為了把 Feature 從Input Image中取出來,那麼通俗來說,Fully connected layer就是為了把萃取來的Feature 對映(Mapping) 到樣本Label的空間(Space)中做Classification,其本質上來說就是一個矩陣向量乘積:
那行是大概如下: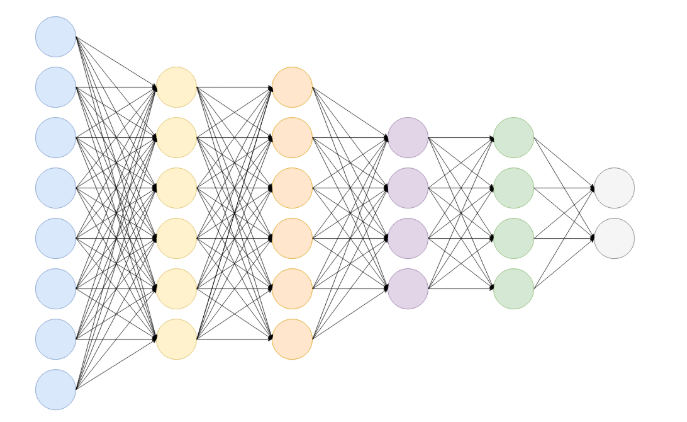
OK,我們知道了 Fully Connected 是一個轉換矩陣去試著 Mapping feature Map 到 Label space,但這是可能會有個問題QQ那麼就是經過 Convolution 計算之後不是一個Feature map 長得是矩陣那種方形的嗎?怎麼就變成一條長的可以跟 Fully Connected做全連接了?????
這邊要介紹一個工具叫做 Flatten:
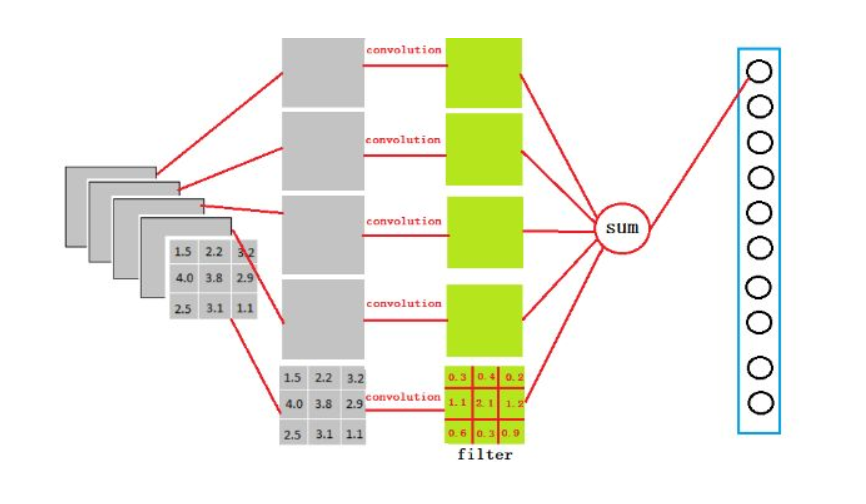
假設我們有5個3 * 3的Feature map,然後我們需要用讓他變成4096維然後跟Fully Connected layer 做連結,那麼其實Flatten此時就是 3x3x5x4096 的 convolution layer 去跟 feature map 做 convolution計算得出來,太繞口了嗎?那麼只需要記做下面這張圖就好: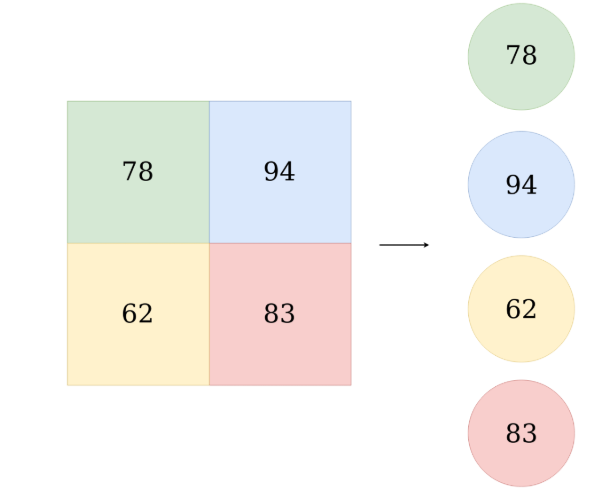
我們的 Model 總算測出來一個甚麼鬼了XD逾時我們可以去找別人開始吹我們的 Model有多猛,但我們需要一個量化的值去說明我們的 Model 有多好,或者換句話說,我們預測出來的值能跟 Ground Truth 有多像。所以這邊我們知道了第一個 Loss Fuction的重點也是最重要的一個重點 :
Loss Fuction 必須要能夠足夠有效地說明你的 Prediction 跟 Ground Truth有多像
所以其實 Loss Function 某種程度上也代表了我們希望我們的 Model 的 Goal,或者說我們想要縮小的、最小化的目標函式是甚麼(Objective Function)
那麼常見的用來做Classification的 Loss function就是交叉熵(cross-entropy)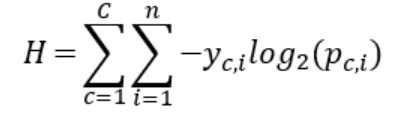
我們總算讓Data完整的經過 CNN model並也得出了如何估量我們跟 Groung Truth 有多像,那麼下一步便是使用每次 Training 得到的誤差反饋給我們的 Model知道要往哪裡進步!!

